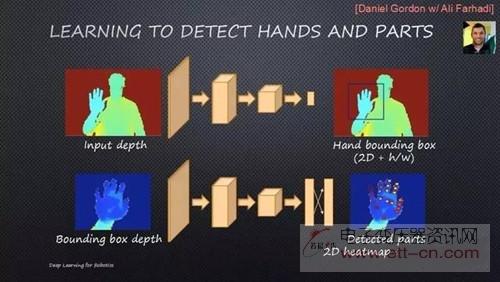
John Leonard一开始说自己是深度学习怀疑论者,但5个月前他看到了LarryJackel做的英伟达自动驾驶有关项目,然后改变态度,认为“让那些不用深度学习的人自生自灭就好了”。Jackel使用的是特斯拉收集的数据,包含摄像头和传感器记录的上亿英里的驾驶训练数据。Leonard还介绍了深度学习在机器人传统概率推理中的应用及未来潜力。
训练数据都从哪里来??
很多讲者都提到了训练数据的问题。Pieter Abbeel强调了OpenAIGym平台可以用于解决合成强化学习机器人问题。
很多人都采用这样的方法:先在合成数据库上做试验,之后再使用现实世界数据进行更复杂的模拟。
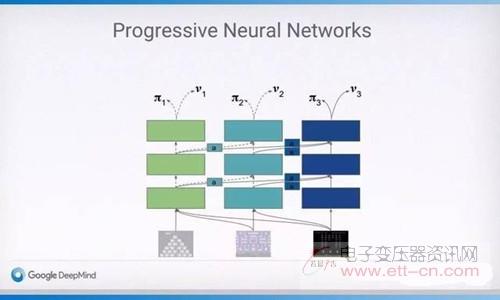
谷歌DeepMind的RaiaHadsell在演讲中提到了PNN非常适用于这一过程。最先是训练系统玩ATARI游戏,然后发展成模拟的三维机械臂控制问题,结果发现使用了预先训练过的PNN框架的系统学得更快、性能更好。


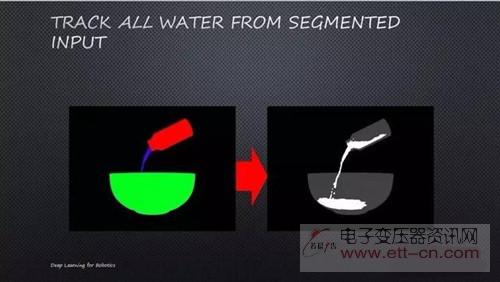
DieterFox的实验室也采取了类似的方法。他们为流体模拟时,先使用混合的流体模拟,然后再使用现实世界的数据。



尚待解决的DL问题
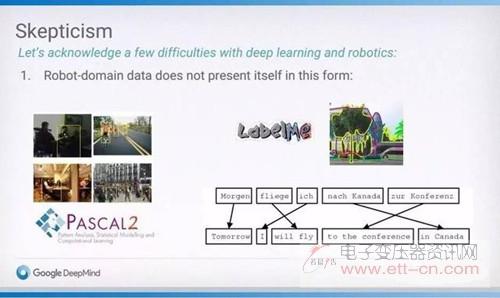
一个经常提到的问题是如何将训练后的深度学习系统整合进应用于现实世界的机器人产品,不论是家用机器人还是自动驾驶汽车。绝大部分讲者认为,将测试中的每一个可能情形列举出来是不可能的,因此必须设定一些标准的故障容差数据集。Scheirer将容差与工厂里依靠统计模型进行测试作类比。NicholasRoy则认为基于模型的方法更好。
WalterScheirer从数据的角度讨论了CNN鲁棒性低的问题。CNN显然适用于单个图像分类任务,但鲁棒性低有时候确实是个问题。Scheirer借用心理物理学(Psychophysics)评价神经网络的方式,测试识别模糊图像和遮挡问题。结果得到了很多性能一流的网络,结果分辨率用人眼看也没有什么显著降低。因此,Scheirer指出,CNN在图像识别方面性能“超人”,但应用起来表现不好,实际上是参数没有设置好,导致算法鲁棒性评估出了问题。
在讨论中还出现了很多有趣的问答。有人问我们用人类使用的数据训练机器,这样的机器是否能够拥有超过人的能力,OliverBrock回答说“AlphaGo”。另一个则是研究中在线训练时间的问题,有人问网络线下训练的权重是否重要时,Raia回答说“是”。不过她之后具体阐述了这个问题,也是谷歌DeepMind在强化学习研究中的核心问题。
总结
最后,Pieter说相比以前,人脑也没有得到很明显的进化,但除了吃喝,我们还从中“得出”了很多充满智慧的发展。